XuSum99
http://www.xanadu.com.au/ted/XU/XuSum99.html
( d28x
99.08.19
To
Ted Nelson Home Page.
MATERIALS RELATED TO THIS ARTICLE:
BASIC Transpublishing
Main Page Transcopyright
article
PARALLELISM "My
Parallel Universe" "Documents
Are Intrinsically Parallel" EXAMPLES
Transpointing
Windows Parallel
Data Structures
Existence Proofs
OSMIC:
Microversioning and Hypertime Backtrack ZigZag
page at Keio
PLEASE NOTE
This article is still being revised.
It has been tentatively accepted for the ACM Computing Surveys
hypertext
issue.
|
Xanalogical Media: Needed
Now More Than Ever
SUMMARY.
"Literature" is what we call persistent media.
The constructs of electronic literature are arbitrary and offer great possibilities
yet ignored.
Electronic literature, after decades of little progress,
has recently developed fast, but badly. The selection of literary
constructs-- primitives for owned, persistent media-- has been crude.
In particular, the World Wide Web is a delivery system for separate closed
units-- a system which allows only embedded links pointing outward.
This is simple but naive-- creating a tangle of ever-breaking one-way links,
breaking whenever documents are moved or modified. It postpones the
real problems.
The two-way link problem is merely dismissed; the more
fundamental problems of intercoparison, version management, the correspondence
of versions, and link maintenance as versions change, are not approached.
Nor is the vital literary relation of transclusion (the management and
intercomparison of identities of content among documents and versions).
Rights management is not considered to be part of the structural model,
but a separate legalistic issue to be handled by different mechanisms unrelated
to the structure of documents.
By contrast, the xanalogical model of electronic media
(best known by one trademark, Xanadu*) was always concerned far earlier
with these deeper problems, and proposed to solve these problems with a
specific simple structure. This structure handles version management,
rights management, quotation management, the connection of quotations to
their originals, the ability freely to quote without negotiation in any
amount and to recomposite in any amount.
Central to the design are the literary constructs of 2-way
content link, transclusion, and transpointing windows. The Xanadu
system has always been a specific structure on any scale, though with different
details, on which a specific publishing system was designed. Later
Xanadu designs center around a unified address space for persistent media
elements and its recognition by editing programs, caching methods and payment
systems.
There is still a prospect for a serious electronic literature
with these desperately-needed features; our work now concerns how to add
these features to the Net as components on a step-by-step basis.
Components of the Xanadu code developed by XOC, Inc., now available in
Open Source, may plan a useful part.
* An international trade and service mark of Project
Xanadu, Sausalito, California.
Computer people like to simplify problems, and add richness
only as users demand it. Unfortunately, many forms of richness cannot
be retrofitted.
In addition, computer people have been fundamentally naive
about documents and their complexity. Most computer people have evidently
not faced the issues, or tried to understand the general case, of versioning
and intercomparison, which is closely allied with the problem of rewriting
and seriously reorganizing long documents.
Quick wins, impressive to the public, were available to
implementors who ignored all these issues. Such aggressive simplification,
misunderstanding the creative process and misunderstanding documents, media
and literature, has resulted in today's clumsy computer writing tools,
and more recently has resulted in the World Wide Web. The Web reflects
this same oversimplifying and naive attitude, starting with the trivial
and now endeavoring to upgrade it to real text needs by continuing to aggrandize
methods which were inappropriate in the first place and are intrinsically
incapable of getting better. On both the desktop and world-wide scale,
culturally and commercially, we are the poorer for these bad tools.
Now we must live with the broken consequences of the existing
systems; and most important, solve these matters correctly without being
locked to the existing bad decisions.
"The Web versus Xanadu"
Universal decentralized hypertext publishing was designed
originally by the Xanadu Project (1, 2, 7, 9).
Concerned with comments, intercomparison, version management,
link management, and rights management, we found a general and simple design
which solves all of them together, but were unable to deliver software
on a timely basis. For political and epidemiological reasons, the
World Wide Web has taken the niche that the Xanadu project was aiming for.
Many people heard us talk about world-wide anarchic hypertext
publishing, and many still think that was all we were talking about.
Since the Web achieves that, we are often asked how Xanadu is different
from the Web. The two systems are *not similar in any way*, except
that they are both simple architectures-- highly different architectures--
for large-scale distributed hypermedia publishing repositories under distributed
ownership and control. To confuse "hypertext publishing" as implemented
on the Web with hypertext publishing as designed originally by the Xanadu
project (1, 2, 7, 9) is like a misunderstanding where two guys are talking
about "moving into space"-- where one party referring to colonization of
the solar system, and the other to his new office.
The Web has only one-way links and no provision for maintaining
them as documents change. The Xanadu concept, just as simple but
much richer, permits two-way links which stay in place as documents change
and move, and handles version management and rights management with the
same unified solution.
The Web achieves the flashy, easy-to-do 50% of any problem
that Richard P. Gabriel talks about (3). It is built out of separate
closed units defined by embedded markup. The embedded markup
mechanism is used also for outgoing links. This has several immediate
drawbacks. It prevents marking up the material simultaneously in
other ways (unless it is copied and loses its identity (4)); and it legislates
firmly against two-way links or even links which overlap.
On the Xanadu project, we fully foresaw the danger of
such a widespread hypertext universe with ever-breaking one-way links and
no principled re-use of material; with no version management, no rights
management, no parallel intercomparison, and no principled re-use of content
materials. We were working for a much better world. In other
words, the World Wide Web is precisely what we were trying to *prevent*.
Our design is concerned with parallel viewing and intercomparison, and
the perpetual re-use of material, both privately and publicly-- issues
which Web enthusiasts are trying to deal with piecemeal (XML).
The xanalogical concept and structure, widely misunderstood,
still offers a unified solution to the issues of two-way links, version
management, link management and rights management. HTML is coming
to be appreciated best as output formats, like PostScript. To what
degree XML will be an improvement is difficult to say; while it addresses
some of the issues here, it does so from a starting base of misguided legacy
commitments.
THE PARADIGM CHALLENGE
Paradigms always acquire the magical patina of apparent
certainty. The views and methods of any current paradigm seem to
be the architecture of the universe, rather than someone's arbitrary choice;
alternatives are impossible for many people to imagine. (As a rule,
paradigms can only be perceived in contrast to other paradigms.)
But there are no simple arguments for one paradigm against another.
The differences are global, diffuse and panoramic.
The Xanadu paradigm is very different, simple but difficult
to present. The structure proposed by the Xanadu project (7, 1, 2,
5, 8, and expounded here in later sections) has always been a simple concept,
but remains for most people an unimaginable paradigm challenge.*
*David Durand has says of the defining document,
*Literary Machines* (9): "I never found anyone else who read it as a design
specification and problem statement, even among those who've read it."
1. The XANADU PARADIGM IN
GENERAL-- Versus Files, Hierarchy and Today's Windowing Systems
The Xanadu ideal is to model and enact exactly a new world
that users would want and need if they realized it was possible.
The most general statement of the Xanadu paradigm is this: the purpose
of computers is tracking connections. A new computer world must be
created built around explicit connection. Great efforts must be made
toward this end.
The present computer world is built on crude traditional
models: hierarchy (believed by some to be synonymous with "structure");
paper analogies, machine analogies, spatial analogies; a crude model of
time and backtracking. Older computer
methods have great unseen drawbacks, pushing huge problems out into users'
laps.
Users' needs are ill-addressed by the paradigm of hierarchical
files and their inability to deal with non-overlap. Today's
graphical front ends, all using the arbitrarily conventionalized PARC User
Interface (PUI-- usually called 'GUI') merely sugar-coats this hierarchical
structure. And paper simulation, as in "word processing", is a dumb-down
bargain with the devil. The assumption of printout as a canonical
form of information (the role of the Xerox Corporation here was no accident)
are clumsy constructs, entrapping the user in their irrelevant ramifications.
The same goes for "Folders", the so-called "Desktop" and worst, the pernicious
"Clipboard". Machine analogies and spatial analogies are just as
misleading.
We need instead a rational representation of structure--
from computer mechanisms to electronic literature-- around the representation
of all connection, rather than on false approximations (eg copying).
This includes a different approach to files (making their contents more
streamlike). Most important, it means system-maintained connections
in vast quantities.
The objectives are: the escape from paper, finding the
best ways to support human thought and creativity-- building on a sophisticated
knowledge of complex documents, not building up from the simplest implementation
of the simplest documents. The search is for an orderly, fast-evolving,
fast-accumulating universe of electronic documents, not modelled to paper,
and showing detailed relations among documents and versions, including
overlap and commonality.
2. The XANADU PARADIGM
FOR LITERATURE
Hypertext is a predestined form of media. Just as
writing was implicit in speech, hypertext is implicit in writing.
Hypertext and hypermedia are the manifest destiny of media (data objects
with creators and points of view) and literature (media we keep).
A literature is an the media that get saved (including
films, audio, etc.)-- an overall system of documents, publications, their
ownership and persistence. Today's paper literature is complex and
highly evolved. Such concepts as "document" and "version" are literary
concepts. Document and version boundaries are implicit in the sytem
of literature. Authorship and ownership of content are also part
of the literary system. Quotation, which brings in materal across
a document boundary, is a literary construct.
Today we face the challenge of designing a new literature.
The issue is how to design a literary system for both change and continity,
with the ability to present such literary concepts as alternative structures,
disagreements, forms of evidence, correspondences, annotation and side-by-side
intercomparison. (Thus parallel hypertext is crucial.)
These are the basic concepts of the Xanadu paradigm.
They have led to a number of emergent objectives-- design aspects of the
intended system that will live up to these ideas.
EMERGENT OBJECTIVES 1: SIDE-BY-SIDE
VISUALIZATION AND USE (PARALLEL HYPERTEXT)
From the begining, we designed in the Xanadu
design for one fundamental visualization. This visualization would
allow annotation (in a parallel window), intercomparison (in a parallel
window), link following (in a parallel window), and many other functions.
Working backward from this visualization, all information
structures had to be set up for sideways interconnection and presentation.
That is what the Xanadu project has been about.
The basic visualization is very simple. The following
pictures of it were published in 1972 (9). They propose, and illustrate,
a generalized method for showing connections and correspondences on a computer
screen.

The 1972 mockup: connections between contents of windows
The first picture shows a user sitting at a mockup of
a windowing system where content within one window actually connects to
content within another window. I have recently proposed the
term *transpointing windows* for this interface (8), but clearly it is
not just an interface, since mechanisms are required to implement this
structure. I believe such an interface and structure offer far higher
capability than the windowing systems we have today (which I believe were
designed later).

Closeup of the 1972 mockup. The idea is that
the transpointing lines remain connected to content
even as the content scrolls or the windows move.
Why have such windowing systems for intercomparison not
become available? I believe they are needed everywhere, in virtually
every activity. I think the answer is twofold: those who knew it
was possible saw no point (since they knew enough to get a lot of payoff
for doing much less); and those who appreciated the need-- if there were
any who appreciated it-- did not imagine it to be possible.
EMERGENT OBJECTIVES 2:
PROFUSE BIDIRECTIONAL OVERLAPPING
LINKS WITH MANY OWNERS
If we are to have a serious pluralistic hypertext
literature, it is necessary that anyone be able to make links to anything,
and this means that the links must be able to overlap. This means
that hundreds (or hundreds of thousands) of user-authors must be able to
make links to the same or overlapping portions of the same material.
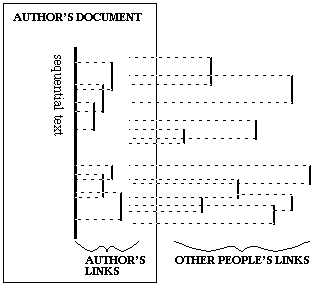
The link-anchor is thus a pernicious idea, based on the
notion of small numbers of links to eligible locations which must be individually
prepared.
EMERGENT OBJECTIVES 3: TRANSCLUSION
COMPARABLE
The Central Transclusion Concept
We need to able to recognize shared material, and see
it side by side. Such a capacity must be supported at the system
level, for managing and intercomparing identities between documents and
versions.
*While the word "transclusion" has caught
on here and there,
it has been widely misunderstood, and confused
with
the computer mechanism of call-by-reference.
For this reason I have more recently
proposed the term
*hyper-sharing*
for the intercomparable presentation of
identical contents (22).
Transclusion must be system-supported, not added at the application
level. Such a facility, at the system level, is vital for many study
and organization purposes. This is transclusion.*
Actually transclusion is a *literary* concept. Literature
is the system of what gets saved, esp. documents, publications, their ownership
and persistence. And such concepts as document and version and their
boundaries are literary concepts. Therefore transclusion-- recognizing
and seeing contents across such boundaries-- is a literary concept.
PHILOSOPHY OF TRANSCLUSION
Transclusion is an answer to the problem of understanding
identities of contents-- seeing what things are the same in two documents,
side by side (as in the above visualization of transpointing windows).
Because this idea is not widely recognized as important,
let us consider its origins from several directions.
OFFICE ORIGIN OF THE
TRANSCLUSION IDEA. There are numerous paper methods that
refer to some original: making copies; cross-indexing (with notes that
say "see elsewhere"); cross-filing (putting several copies of the same
document in different places where it might be sought). ALL THESE
ARE CRUDE APPROXIMATIONS OF SOMEHOW PUTTING THE SAME THING IN ALL THE RELEVANT
PLACES, SIMULTANEOUSLY CROSS-VISIBLE. All these approximations require
correcting a bunch of copies every time an original changes.
COMPUTER ORIGIN OF THE TRANSCLUSION
IDEA. All digital copies implicitly refer to an original.
Why cannot the connection to the original be maintained? Multiple
copies, or other approximations to the correct relation, is a crude simulation
But making this connection to the original explicit, and
maintaining such connections at the system level, requires different and
expensive steps and a major commitment.
The steps required are expensive and require a major commitment.
But this proposal represents a tenable design philosophy. But it
requires extremely radical changes in the way everything is done.
LITERARY ORIGIN OF THE TRANSCLUSION
IDEA. In so many things we read,
study and research, we must track the origins of content.
Transclusion for versioning: Authors
need to keep track of versions, and where some part of a version came from
(often a previous version).
Transclusion for the safety of our writings. Today's
computer systems are perilous for authors, because there are so many possible
ways to lose work. But if everything an author typed in was appended
to one long file, and the other documents transcluded material from that
file, it would be much safer for the author's work-- NOT LOSING CONTENT,
appending all inputs immediately and referring to them thereafter.
Transclusion for overlays. There is currently
no way to create overlays on the Web, and if there were, such a facility
it would probably be necessary to use some of the content in order to highlight
it.
Transclusion for drill-down access to original materials.
We
read reviews of many books and films we can never have time to read or
see. The reviews are tantalizing because they offer quotations which
we cannot follow. But what if excerpts were available from the review?
What if we could jump at once from an excerpted shot to the film itself?
It would be a vast improvement if a review could give direct access to
the corresponding part of the actual work. These are examples of
transclusion.
Transclusion for explanations. In order to create
a document which explains another document, and uses part of its material,
it is necessary to be able to legitimately obtain parts of the content.
It should be possible to annotate and excerpt materials to explain them
better.
Transclusion for Rights Management. If
each quotation could be bought by the downloading user from the original
author, it would greatly simplify handling on-line copyright. This
is the Xanadu model of sale.
All these need the transclusion concept: a way to create
new documents which use portions of existing documents, or parallel documents
which deeply re-use the material. If transclusion (or visible identity,
or hyper-sharing) is available at the sytem level, we are all richer.
It is possible to implement this.
EMERGENT OBJECTIVES 4: LINKS
X TRANSCLUSONS
The standard explanation of Xanadu systems (2)
has generally distinguished between two orthogonal forms of connection:
links (connections between things which are different) and transclusions
(inclusion from across a document or version boundary; or connection between
things which are the same). Link and transclusion must use different
mechanisms: to implement transclusion by the same pointer mechanism as
links prevents their use in a complementary fashion, for example with the
same links to all instances of a transclusion.
EMERGENT OBJECTIVES 5:
A NEW COPYRIGHT ZONE
Delivering and Selling material across document
boundaries, or "tramspublishing"-- our copyright concept-- is likewise
a literary issue (21, 23).
The traditional contrast is between defended copyright
(requiring relatively complex negotiation and prepayment for use) and public
domain (material which may be freely quoted and XXx.
The idea is to create a new middle realm, one which renders
copyright benign and flexible. This method will extend
the benefits of quotation and anthologizing without negotiation to copyrighted
material. As construed, we consider it to be benign, fair, honest
and cheap. It is a win-win system, as it is beneficial both to rightsholders
and to users, in a way that other copyright systems are not beneficial
to users.
The method is basically simple:
deliver each quoted portion from the original (or a cache) controlled by
its publisher. If payment is involved, payment is proportional
to each publisher from each user who downloads material from that publisher.
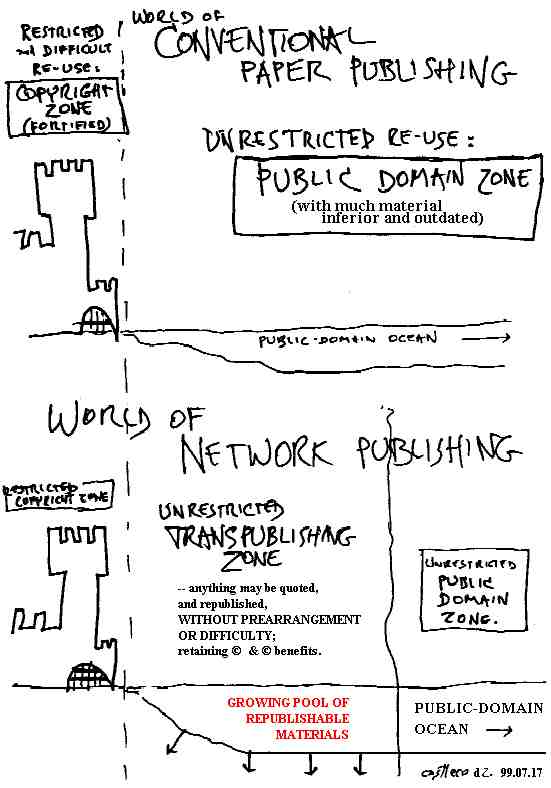
There are several advantages. It uniquely offers
everyone the ability to re-use and recomposite materials from many sources
without negotiation, making many materials easily includable, facilitating
ease of recomposition as if the material were in the public domain.
And it provides direct access to the original context of every quotation.
SUMMARY OF XANALOGICAL VIRTUALITY
The literary constructs of the Xanadu
system are simple: parallel hypertext (showable, for instance, in transpointing
windows), and showing links and transclusions (showing, for instance, as
bands stretching between parallel documents and versions).
Over the last four decades, we have had a number of designs
for doing these things.
For explanatory value, let me discuss first the internal
design of 1972, which was the design underway when those earlier pictures
were made.
The 1972 Internals
In order to show a link on the screen as illustrated in
the transpointing windows above, each document must be kept aware of the
link, and somehow both ends of it. This makes it possible to project
the relevant points in each document through to the screen and the user
interaction layer.
This was essentially the Xanadu design of 1972: connections
are defined between document positions in pairs of individual documents.
(Transclusion was omitted from that design.)
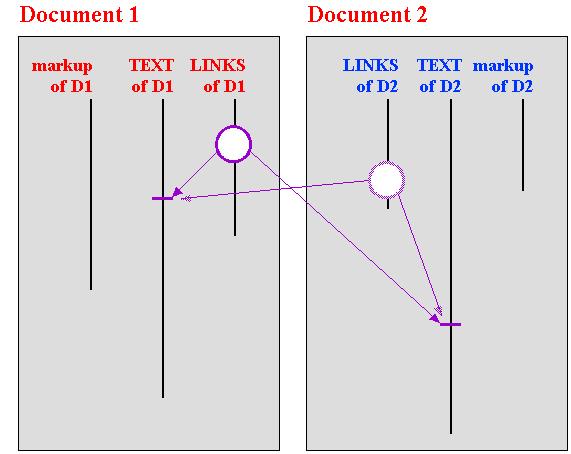
1972 Xanadu design (simplified):
link pointers reciprocated between documents
Unfortunately, keeping track of such specific
connections within pairs of documents is hopeless in the general case.
If the mutual connections between two documents must be recorded in each,
the combinatorial explosion becomes disastrous as the number of connected
documents grows. And this certainly does not begin to handle the
problem of maintaining links as versions succeed each other.
The greater question-- how to do this for many windows,
and for many documents, having such connections-- opens up the issue.
That is what we have worked on since.
The Gregory-Miller Generalization
This design was radically changed and perfected in about
1980 by Roger Gregory and Mark Miller of the Xanadu Project, as described
in *Literary Machines* (2). They generalized it for linking among
many documents and to allow the sharing of materials among documents and
versions. This became the basis of the Xanadu 88.1 implementation
(2).
This method assigns all media elements to a grand address
space. The universal address space includes not just addresses for
the documents themselves, but assigns addresses to the actual *contents*
of documents and versions, *rather than to particular positions in them*.
This gives a unique universal address to all media elements, such as text
bytes or video frames.
The link is no longer between particular documents.
Now the link can be made between the actual contents of one document and
the actual contents of another. In this more general design, the
link refers to these elements by their grand addresses, and ignores the
internals of individual versions.
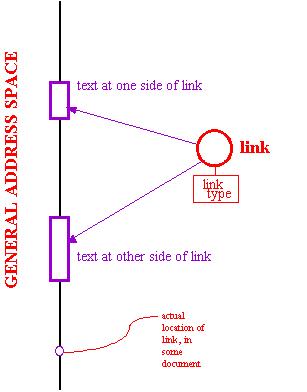
Generalized address space attaches link to contents,
which therefore may be seen in all versions.
(The link itself also has an address in the general
address space.)
This then solves (in principle) the issue of how to maintain
links among versions. It means that contents may be poured and moved
between versions without dislocating links. The stabilized address
structure means that any re-use of the same contents will have the same
links, in whatever documents or versions they are used. From any
version it is possible to find the same links on another version, provided
that any of the elements remain.
(However, the mechanical steps of following a link have
an entirely different structure (2), also discussed below.)
XANALOGICAL STRUCTURE
This leads to a full definition of Xanalogical structure,
as generalized from the Gregory-Miller model. (Note that models with
these levels were in our designs starting in 1960, but the Gregory-Miller
model resolved a number of difficulties with it.)*
* Those who are interested in Xanadu archaeology
will be interested
in small variants of these designs, but
these need not concern us here.
The interior structure below this conceptual design has several
levels.
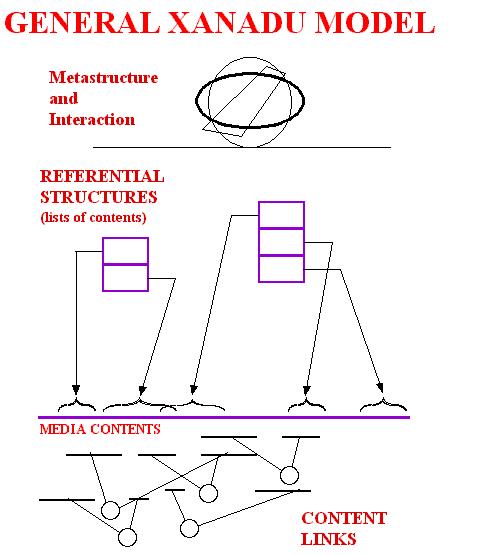
Virtual streams or scrolls of registered media, append-only--
text, audio samples, video frames.
Simple constructs (lists and sequential prose) are constructed
virtually out of reference pointers to this material.
Secondary constructs and interaction applied to these.
Links and transclusions have been represented by different
means in different designs. Since 1981, with the Gregory-Miller generalization,
content links have been defined on ranges of lower-level elements.
Transclusions are not specifically represented, but recognized by this
system as identical ranges of the address space.
THE THREE-LEVEL MODEL*
[first presented 1968]
Note that all these are at the conceptual level,
MAY BE VARIOUSLY IMPLEMENTED *variations to be discussed
By conflating all these levels into one closed structure,
the embedded markup languages paralyze and constrict what can be done.
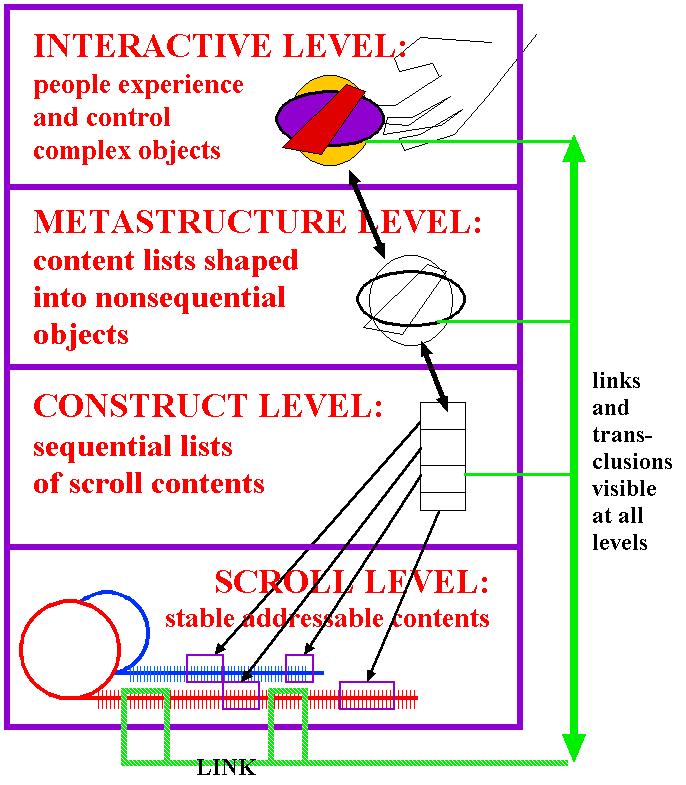
INTERACTION LEVEL
where content of the virtual documents is presented
and manipulated
Metastructure: further levels of construction
Content pointer lists:
REFERENCE LEVEL: Virtual Documents
and Virtual Versions
REFERENTIAL CONTENTS
CONSTRUCTIONS OF ITEMS into
ARBITRARY STRUCTURES
pointers at the scroll level of data provide for the
rearrangement of content
SCROLL LEVEL
VIRTUAL STREAMS, their identity
and addressing
of stabilized data
REFERENTIAL REPRESENTATION OF DOCUMENT
This changes the nature of a document's digital
representation. Documents defined in such a space must be represented and
edited differently.
The canonical form of a document or version now must be
a list of content elements. (The document may be delivered in other
forms, but regardless of how it is delivered, the referential form defines
it-- as a structured list of pieces.)
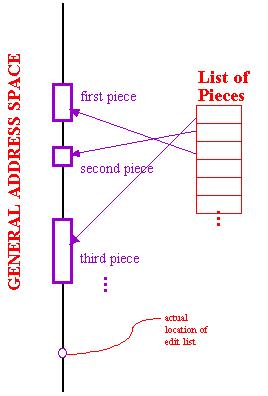
Note that the general operative concept may now be called
the *version* instead of the "document", since there is no implementation
difference between a version and a document, only the difference in the
metastructures of naming and ownership; and "version" becomes the more
general term.
VIRTUAL (REFERENTIAL) EDITING
Because a document or version is now a structured
list of contents in a generalized address space, editing needs always to
maintain reference to this address space. While the characters of
text will necesssarily be present in the editing program, the editing program
must also keep track of their universal addresses, and the result of editing
must be the referential form, a structured list of pieces.
There is a psychological barrier to the acceptance of
this method. It is hard to explain why it is needed, especially to
those in the "text is a simple application" school of thought. Because
characters are easy to copy, it seems an unnecessary level of indirection
to maintain the universal address of each character as well as its representation.
However, there is one area where referential editing is
well established and accepted: video and film. For years in the video
industry, the product of a final edit has been the list of video shots
in a final version (Edit Decision List, or EDL), together with effects
intended to take place on them. This is now also the case in films,
through the influence of such non-linear editing systems as the Avid.
However, to use this method for editing text rather than
just video, we will also need text editing systems which similarly maintain
such a referential form, in which contents are not merely moved around
(as in most word processors), but retain also their original identity in
the generalized address space. The editing system must recognize
the identity of all text contents in the general address space, and maintain
their identities as the document evolves. An example of such an editor
is OSMIC, which may be found at http://www.xanadu.com.au/ted/OSMIC/OSMICpage.html.
(There is a key difference between text and video in this
regard: in the case of video and film, the contents are static, meaning
that the person editing does not create new shots as needed, but rather
makes do with the shots on hand. In the case of text, however, an
author may continually add contents while making other editorial changes.
This means that new text must be continually assigned universal addresses
as it is being created. This is the case with OSMIC.)
CONTENT LINKS AND TRANSCLUSION--
OVERLAP MECHANISMS
Putting the links on content creates a clean design.
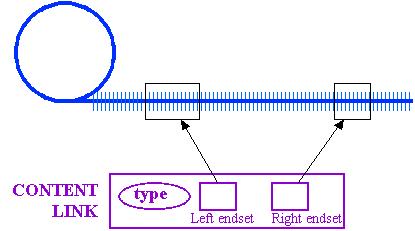
But the issue is, of course, the problem of a vast number
of overlapping links. Since in principle any number of links may
attach to a given range of characters in a document, the process of following
a link is far more complex than with (say) HTML. Given a specific
stretch of elements, the problem is checking what endsets overlap the selected
stretch, establish what links attach to that stretch, and negotiating,
from among that potentially huge number of links, those which are of interest
and following them.
In other words, it is a complex selection problem on a
potential database. This is what is addressed by "XOC Green".
VERY BRIEF HISTORY OF THE XANADU
PROJECT
From 1960 to 1979 I operated mostly alone. In 1979
a stable group united around the project. Nine years later in 1988,
the project was acquired by Autodesk. After four years we experienced
sudden decompression when Autodesk dropped the project.
We have not been much in touch with the rest of the world
because our views of what was important, and the right methods, was totally
different from anyone else's. However, some seem to think that our
software concepts were invalid because we did not deliver product.
This is absurd. The project suffered from the "too many cooks" syndrome
at both design and administrative level. (Everyone believed the project
was important, and there was a good deal of jockeying to influence or control
it.) Incidentally, my own role was reduced to spokesman and eventually
fall guy, by the so-called "Silver Agreement", which barred me from a role
in design or administration.
In any case, the whole system was designed backward from
the aforementioned concepts of parallel hypertext-- parallel intercomparison
and annotation with bidirectional links and transclusion; and from the
idea of transclusive publishing, where the unit of sale of content would
not be the book or magazine but the sentence or paragraph, micropurchased
in arbitrary constructions which anyone could create. We anticipated
a unified, CompuServe-like, service that would provide storage and publication
services, and manage fractional royalty payment for every download on an
exact and fair basis that would facilitate unrestricted virtual republishing.
These ideas are still valid, and are now being redesigned
in pieces for the Net.
XOC, Inc. retained the rights to the software as developed
under Autodesk, and has now officially decided to make this code available
under Open Source. The designated node for finding the material will
be open.xanadu.com.
Rethinking the Xanadu Project
for Today's Environment
These structures are just as good as they ever
were. This is still a valid and powerful paradigm, a deep-seated
and principled alternative to hypermedia-- and indeed the computer world--
as we know them today.
Since the 1992 decompression and the 1994 explosion of
theWeb, I have been thinking over how these ideas may be transposed to
today's Internet environment. This meant separating out a number
of constituent ideas.
The fundamental design-- referential documents and versions
selecting content from stable, addressablemedia which bear the links--seems
to me as good as gold. The problem is how to XXXX for the present
environment.
The different implementation structures below handle different
aspects bringing of the design to the distributed model of today's Internet.
WHAT IT WILL TAKE
The idea is simple, but diabolically tricky to
explain. This was true of the other YYYY, now of ZZZ the idea The
same applies to the components of the distributed system. The YYYYY
piecemeal to today's Internet, but to enumerate the pieces makes them sound
complex and disconnected, which they are not. Overriding concepts
include:
*Transcopyright* (21). Transcopyright is
the enabling legal doctrine, endorsed by lawyers, to enable unfettered
virtual transpublishing without negotiation.
*Transpublishing* (23,24). Transpublishing is the
delivery of quotations from own publisher (or some virtual equivalent).
This requires transquotation servers (21, 23) which will deliver small
selections on request.
A number of specific services by Internet Service Providers
(ISPs), not yet available--
long-term guaranteed publishing (this is not
a technical issue, but a business promise, comparable to insurance);
address servers allowing content itself-- not merely closed
titles-- to have a plurality of address locations, not merely closed titles;
micropayment which may be interposed before delivery.
Other components are needed in the user's system, particularly
caches and editors which know the generalized ID of contents.
And finally, and most important-- a comparison browser
based on transpointing windows. At the University of Southampton,
Ian Heath and I have created an interesting implementation which manages
such connections and their scrolling. (24). We have a working demo
which enacts fully the functions of the 1972 mockup pictures.
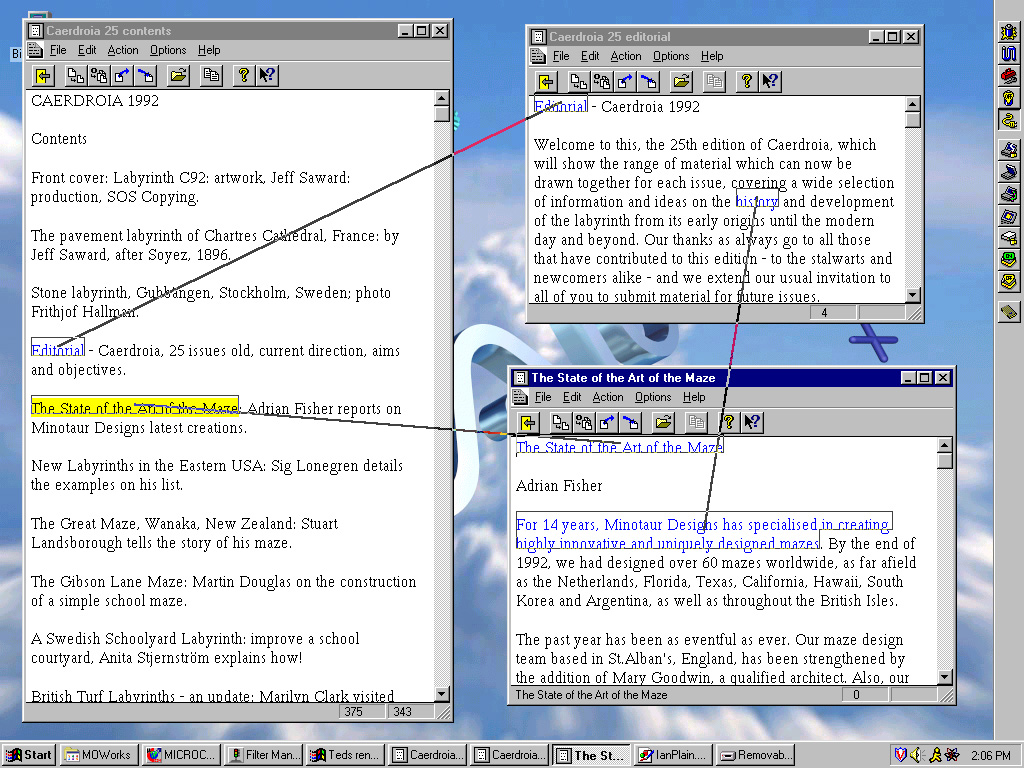
As these windows are scrolled or moved around the screen,
the lines adhere to the content, as in the original specification published
in 1972.
(Note that this was programmed according to what
we refer to above as the the 1972 method.)
Even computer sophisticates express surprise that this
is possible.
Influences of the System
Claims that "Xanadu was a complete failure" are
absurd. While we have not yet delivered any product based on these
designs, the influence of the Xanadu project has been considerable.
For instance, to mention only acknowledged instances:
Tim Berners-Lee cited our ideas in his original proposal
for the Web [URL]
Lotus Notes came out of a discussion between Ray Ozzie
and the author (14);
Microcosm, inspired by the Xanadu work, uses external
parallel links with great success (10, 11, 12);
HyperWave uses transclusion at a large-grain level,
as inspired by our work (15);
Sam Epstein's Imedia system uses transclusion as a
unifying concept for a networking version of Lambda Moo (16);
Miller & Ping's "Crit" (18) has a Web-specific
form of commentary visible through proxies.
Possible Effects on the Computer
Field Itself
The emerging role of the computer as a media
machine is clear, but its consequences are not generally recognized.
One is that media contents will be ever-arriving and ever-growing.
Users will accumulate digital material in vast quantities, much of which
will be re-usable in new contexts. This means is that content will
need persistent identities based ever-changing projects as well as copyright
ownership, and that computers will need to be set up for the rapid and
routine acquisition of vast amounts of content. Being able to make
links to this content, wherever used, will be vital.
At a deeper level, there is a great deal of traditional
structure in computer files and programs, whose clumsiness is seldom acknowledged;
which might well benefit from fine-grained linkage and transclusion as
system facilities.
RELIGIOUS ISSUES
There seem to be many levels of emotionalism
and personal identity involved with the issues discussed here. They
certainly are not merely technical. The Xanadu idea has challenged
many people's notions of closure, connectedness, completeness, hierarchy,
and proper style of work, publication and ownership.
Those who see subjects as bounded and hierarchically related,
who see research as final, who see education as memorization and skills,
who believe there are authorities who really understand things, who don't
worry about lost information, who don't worry about minority points of
view, who don't see the need to express alternatives, who don't see a need
for intercomparison, who don't see a need for literary continuity, and
who believe that work must always be finished and closed, have a great
deal of difficulty with this paradigm.
However, for some of us who want to increase the power
and accessibility of media in the future, it is hard to imagine an alternative.
This is still a valid and powerful paradigm, a deep-seated and principled
alternative to the hypermedia-- and indeed the computer world-- as we know
them today.
BIBLIOGRAPHY
Numbered according to current text --
(1) Theodor H. Nelson, "Replacing the Printed Word." (S.H. Lavington,
ed., Information processing 80 (Proc. IFIP 80 World Computer Conference),
North-Holland Publishing Co., 1980, 1013-1023).
(2) Theodor H. Nelson, *Literary Machines*, 1981. Most recent
edition, 1993 (*Literary Machines* 93.1.) Translated also into Japanese
and Italian.
(3) Richard P. Gabriel, "Lisp: Good News, Bad News, How to Win Big"
at
http://www.ai.mit.edu/docs/articles//good-news/good-news.html;
especially section entitled 'The Rise of ``Worse is Better'''
http://www.ai.mit.edu/docs/articles//good-news/subsection3.2.1.html
(4) Theodor H. Nelson, Embedded Markup Considered Harmful. In
XML: Principles, Tools, and Techniques (World Wide Web Journal
2:4, fall 1997). Table of contents at http://www.w3j.com/xml/
(5) Theodor H. Nelson, 1987 Xanadu Poster [to be scanned and on line
shortly]
(6) David G. Durand, personal communication.
(7) Theodor H. Nelson, "A File Structure for the Complex, the Changing
and the indeterminate." Proceedings of the ACM National Conference,
1965.
(8) Theodor H. Nelson, The Heart of Connection: Hypermedia Unified
by Transclusion. CACM August 1995, vol 38 no 8, pp. 31-33.
(9) Theodor H. Nelson, As We Will Think." Proceedings of Online
72 Conference, Brunel University, Uxbridge, England, 1972.
(10) Davis, H.C. "To Embed or not to Embed", CACM, 38 (8), pp108-109,
August 1995.
(11) Wendy Hall, personal communication.
(12) Hugh Davis, personal communication.
(13) Ian Feldman, "What Is Setext", at http://www.bsdi.com/setext/setext_concepts_Aug92.etx
(14) Ray Ozzie, personal communication.
(15) Hermann Maurer, personal communication.
(16) Samuel Latt Epstein, personal communication.
(18) Available at http://crit.org.
(19) Richard M. Stallman, personal communication.
(20) Theodor H. Nelson, "Transcopyright: Dealing with the Dilemma of
Digital Copyright." Educom Review 32:1 (January/February 1997), 32-5.
(21) Theodor H. Nelson, "Transcopyright: A simple legal arrangement
for sharing, re-use and republication of copyrighted material on the Net."
Keynote at WWCA '97 conference, March, 1997, Tsukuba, Japan; published
in Takashi Masuda, Yoshifumi Masunaga and Michiharu Tsukamoto (Eds.), Worldwide
Computing and Its Applications (proceedings of the WWCA '97 conference,
Tsukuba, Japan, March 10-11, 1997.) Springer-Verlag, Berlin, 1997.
ISBN 3-540-63343-X. Pp. 7-14.
(22) Theodor H. Nelson, *The Future of Information*, 1997. Available
on the Web at http://www.xanadu.com.au/ted/INFUTscans/INFUTscans.html.
(23) Theodor H. Nelson, "Transpublishing: A Simple Concept", at http://www.xanadu.com.au/ted/TPUB/TPUBsum.html
(24) Theodor H. Nelson, "Transpublishing for Today's Web: Our Overall
Design and Why It Is Simple". At http://www.xanadu.com.au/ted/TPUB/TQdesign99.html
(25) Theodor H. Nelson and Ian Heath, "Implementation of Transpointing
Windows." In preparation.
(99) Theodor H. Nelson, "The Tyranny of the File." Datamation,
15 December 1986.